Simulation
Showcasing the difficulty with LLM-Assisted Simulation Modeling

In the last blog post, I wrote about how, while LLMs have specific strengths and weaknesses (just like any other tool), the current popularity and hype surrounding them is resulting in them being over-applied and being presented as a magic catchall solution.
I hold the belief that, at least within the next 5 years, LLMs alone will not be enough to handle the immense amount of nuance and accuracy that simulation modeling requires. I recently found an example that I thought I’d share, as it does a relatively decent job of demonstrating this.
Take a simple example where we have a “preferred” and “non-preferred” group of resources (e.g., operators). As agents (e.g., callers) arrive, they should prioritize the preferred resource if one is available, otherwise whichever is available first. Here’s a simple animation with the various scenarios that can occur based on this logic:
In the first 3 scenarios, when the call arrives, there is at least one operator available and thus it’s routed accordingly. In scenarios 4 and 5, the operators are both busy at the start, and the a decision is not made until one of the operators become free.
Take note that in 3 out of 5 scenarios (#1, 2, 4), the preferred operator is ultimately chosen, while the remaining two (#3, 5) the non-preferred is chosen (i.e., a 60/40 split).
Code | Translation |
|---|---|
with preferred_operators.request() as request: | Try to get a preferred operator |
result = yield request | env.timeout(0) # non-blocking | (But don’t wait for them) |
if request in result: # got preferred operator yield env.timeout(triangular(0.5, 1.5, 1.0)) return | If you did get a preferred worker, use them and stop here. |
with non_preferred_operators.request() as request: yield request | Otherwise, try to get a non-preferred operator (waiting if no one is free) |
yield env.timeout(triangular(0.5, 1.5, 1.0)) | Then use that operator |
Important to note: the results provided by Claude are not the same as the original logic described above!
Why? If the preferred one is not immediately free, it always will go with the non-preferred operator, even if, say, they’re both busy to start but the preferred gets finished first (thus failing case #4 above).
To demonstrate the effect of this, we can add some counters for when the preferred and non-preferred get used and perform a monte carlo experiment; the results of which will show a 50/50 split.

Besides the previous method of speculating the possible scenarios to deduce the 60/40 split, there’s two other ways we can do a sanity check: using a different tool and checking mathematically.
In this case, I’ll use AnyLogic for the different tool, as it natively supports this behavior, via the alternative resource sets. Putting the same arrival and delay distributions into a model, you can see it essentially reports the 60/40 split.
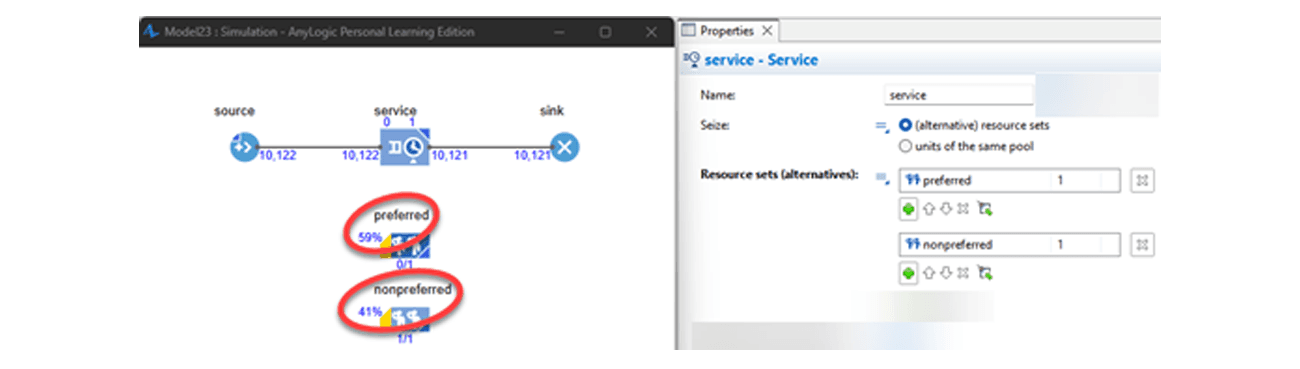
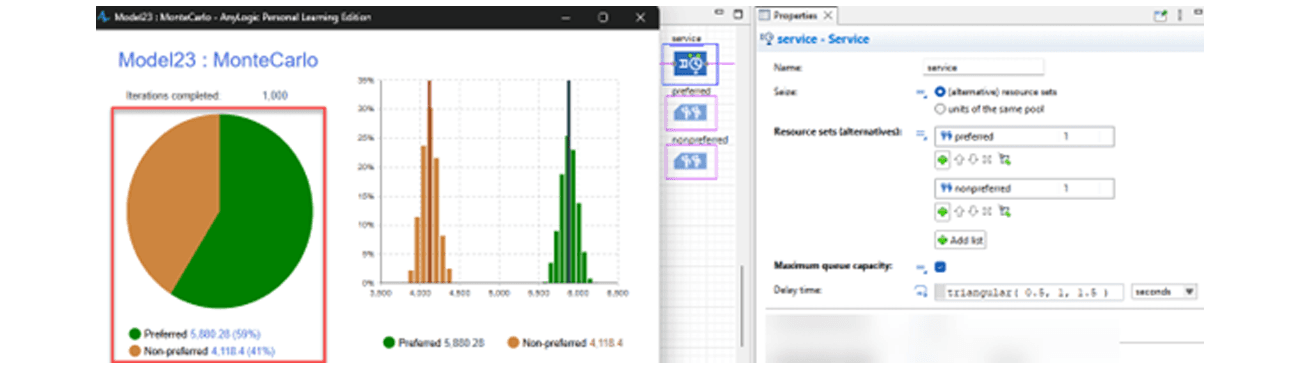
And then there’s the mathematical approach. Depending on the complexity of the dynamics, this may not be feasible, though in this case it is. It’s also the best way to go if you’re skeptical about whether the simulation tool you are working with has the right implementation or not!
In short, going through the math effort provides results in something closer to the 60/40 split. For length purposes, I’ve saved that for an “end of the document” note 😊
As mentioned, it appears the discrepancy is that the Python version (as implemented) does not handle the case when both are initially busy, but the preferred becomes available first. To correctly handle all cases, the code might instead look like:
pref_request = preferred_operators.request() if pref_request in result: |
The next point to make is that due to the probabilistic nature of LLMs, making the same request multiple times can provide different outputs. This is both a blessing and a curse for LLM-powered applications!
When I tried it a second time, Claude gave a completely different implementation. To spare the less code-minded people, I’ll explain the logic it implemented in plain English:
Pull from the preferred group if one was available, then…
Pull from the non-preferred group if one was available (so far so good…),
If neither had availability it forced a selection based on whichever had the shorter queue (🤦♂️).
This seems reasonable, if we were modeling based on vibes. But, in reality, it is equally problematic as the first approach (though in a different way). The problem is that with this implementation, it assumes the longer queue will take longer, which it might not! The inaccuracy of this method is also reflected in the output split, averaging at 55% preferred usage, 45% nonpreferred usage.
The third time I asked Claude, it gave something similar to what ChatGPT and Gemini did – something closer to the correct behavior (i.e., waiting until one or the other was available via the pipe “|” shorthand), but still wrong nonetheless.
However, all three LLM’s failed to produce correct outputs, as they failed to handle for some SimPy specific behavior. Leaving the juicy technical details at the end, the short version is that their naïve ‘understanding’ of some nuances in SimPy causes only the preferred group to be used. This results in error-free code that is logically incorrect – the intention of the written code is incongruous with its executed outcome. This is something that, after seeing the results, might raise alarms in a fleshy modeler, but an electronic one may not detect it!
The focus here is not to judge current LLM providers, but rather to point out a much larger problem with attempting to offload all coding to an LLM. Though, this is not to say that LLMs cannot be used to make larger models though!
Referring back to my previous post, the problematic use-case I’ve detailed here is specifically failing my second area LLMs are optimized for – generating specific content from precise prompts. Though, for cases such as this one, we needn’t expect the user to be specific in the implementation (as they’d otherwise have the information needed to just implement itself); instead, the onus is on a hypothetical backend system which should regulate and inform the LLM with sufficient information so that it could produce the correct output.
The takeaway here: to have an LLM build anything more complex than a single-process model or a single-server queue would require an immense amount of work. While these results may seem inconsequential, bear in mind that this is an extremely simple scenario.
Larger systems will require more of these nuanced decisions to be made, potentially having the inaccuracies compound. Therefore, it’s of vital importance that any automated model building framework be built with enough real, expert logic in place to minimize these types of issues.




Request an invite
Get a front row seat to the newest in identity and access.